"Without big data analytics, companies are blind and deaf, wandering out onto the web like deer on a freeway."
Geoffrey Moore
Machine Learning verleiht Systemen die Fähigkeit selbstständig zu lernen und sich durch Erfahrung zu verbessern. Ein Machine Learning Modell lernt ähnlich einem menschlichen Kind – es erkennt Muster und Gesetzmäßigkeiten in vorhandenen Datensätzen, kategorisiert und trifft Entscheidungen.
Die Anwendung von Machine Learning bietet sich erst bei einer soliden vorhandenen Datenbasis an, kann aber mit geringem Aufwand zu großen Verbesserungen führen.
Einteilung von Machine-Learning-Modellen
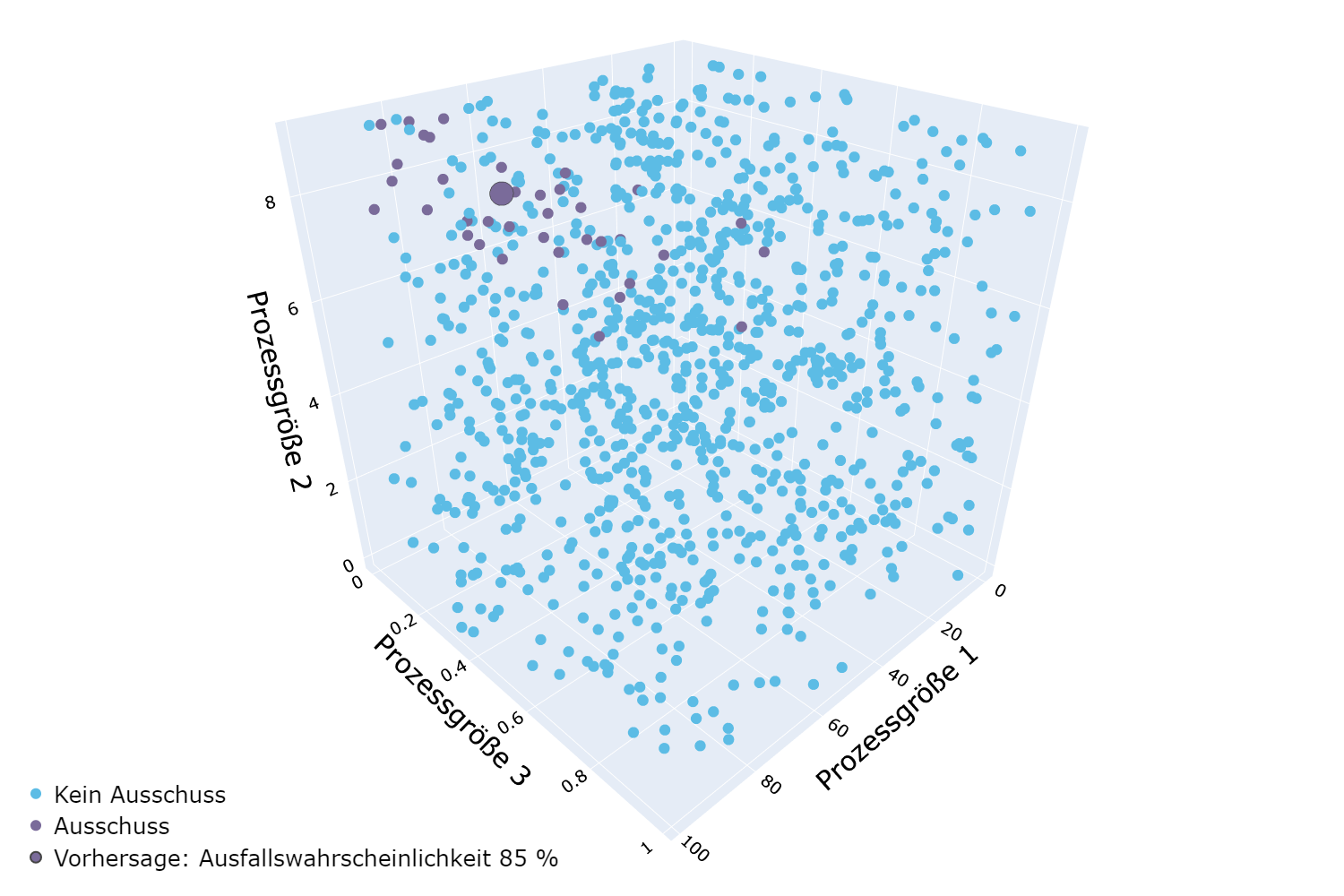
Klassifikation
Unterteilung von Datensätzen in Kategorien, und Vorhersage der Kategorie neuer Datensätze
Beispiel: Kategorisierung von Produkten als Ausschuss noch während des Produktionsprozesses
Regression
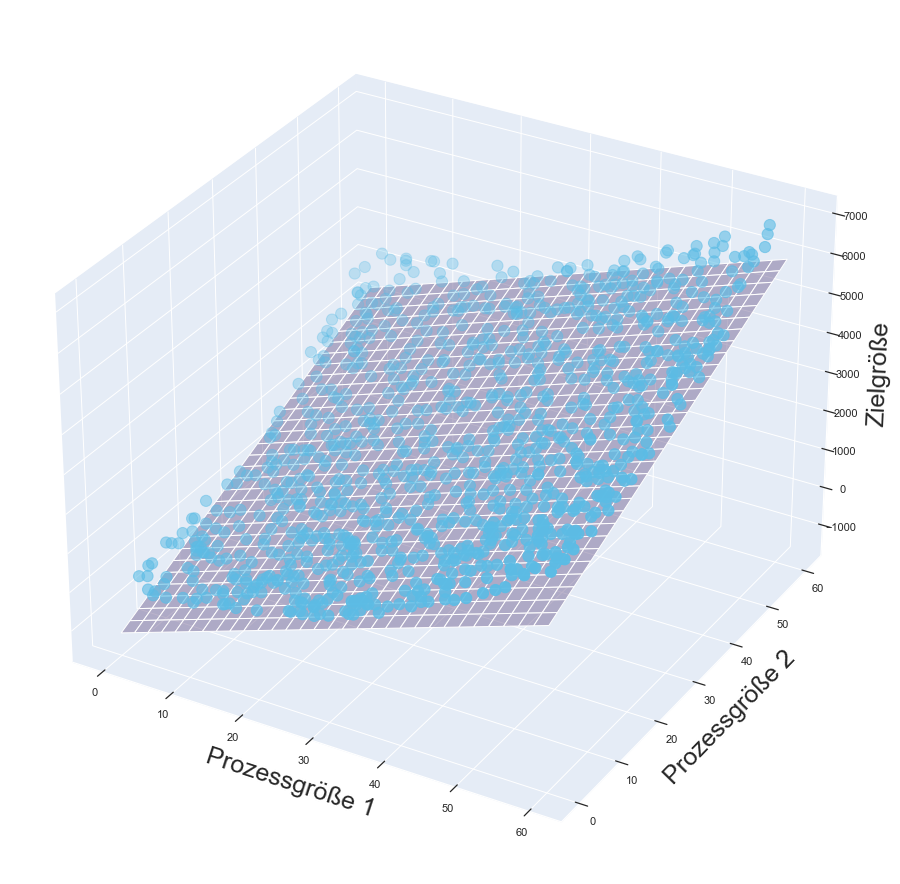
Erkennen von Gesetzmäßigkeiten in vorhandenen Datensätzen und Vorhersage eines Zielparameters für neue Datensätze
Beispiel: Vorhersage der optimalen Materialzugabe für folgende Prozesschritte
Clustering
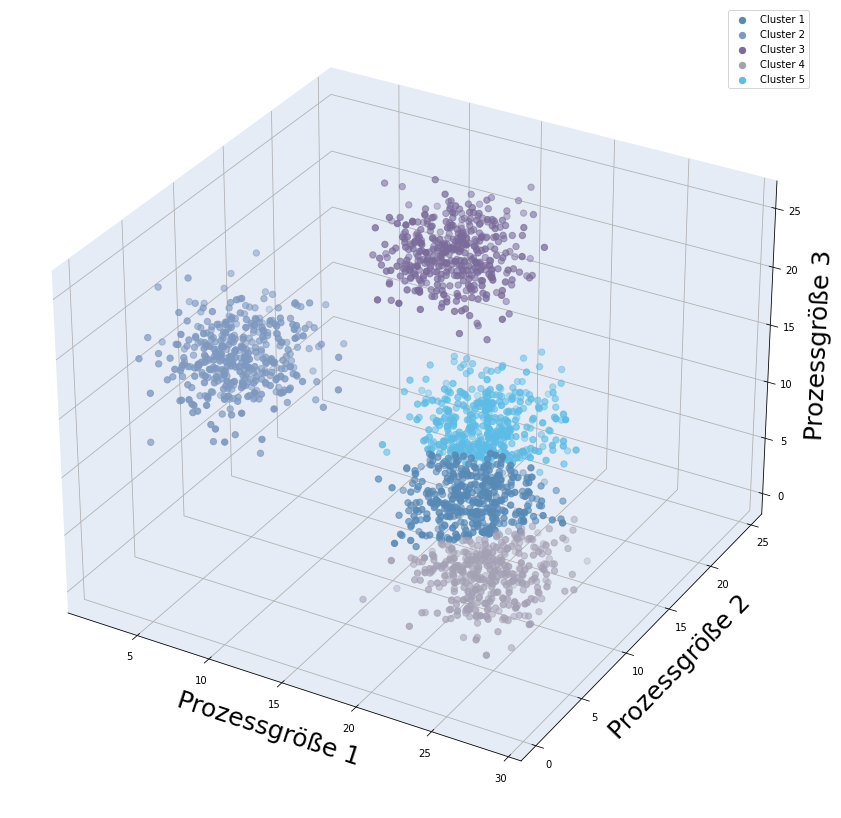
Unterteilung vorhandener Datensätze in (bisher nicht bekannte) Kategorien
Beispiel: Segmentierung von Kunden, Produkten oder einzelnen Produktionschargen
Sie vermuten Potenzial, verfügen aber noch nicht über die geeignete Datenbasis?
Werfen Sie einen Blick auf die Leistungsübersicht!
Prozessablauf
Definition der Anforderungen
Definition von Zielen, Struktur der Eingangsparameter und Modellanforderungen.
Datenaufbereitung und Bewertung
Nach Übermittlung von Testdatensätzen werden diese aufbereitet. Erste Modelle werden entwickelt und nach mathematischen Kriterien hinsichtlich ihrer Aussagekraft beurteilt.
Entwicklung und Bereitstellung der Modelle
Nach erfolgreicher Entwicklung werden die Modelle entweder eigenständig oder integriert in eine Softwareapplikation bereitgestellt.